Spatiotemporal Analysis
Overview
Epidemiology has a long history of studying factors that affect the variability of the incidence or mortality of infectious and chronic diseases. Among those factors, geographical (or spatial) variations of health outcomes have played a crucial role in evaluating health care distribution and performance. Spatial variation in health outcomes has also provided evidence of patterns of dependence and level of noise in the data. More recently, time-series analyses have been used to examine the manner in which health variables vary over time. Spatiotemporal analyses have the additional benefits over purely spatial or time-series analyses because they allow the investigator to simultaneously study the persistence of patterns over time and illuminate any unusual patterns. The inclusion of space-time interaction terms may also detect data clustering that may be indicative of emerging environmental hazards or persistent errors in the data recording process.
Description
Spatiotemporal data analysis is an emerging research area due to the development and application of novel computational techniques allowing for the analysis of large spatiotemporal databases. Spatiotemporal models arise when data are collected across time as well as space and has at least one spatial and one temporal property. An event in a spatiotemporal dataset describes a spatial and temporal phenomenon that exists at a certain time t and location x. An example would be that of the patterns of female breast cancer mortality in the US between 1990-2010, where the spatial property is the location and geometry of the object – US states with breast cancer mortality rate information, and the temporal property is the timestamp or time interval for which the spatial object is valid – 1990-2010 breast cancer mortality years. Other applications for spatiotemporal analysis include cases in the domains of biology, ecology, meteorology, medicine, transportation and forestry.
Challenges Unique to Spatiotemporal Analysis
While this approach can provide new dimensions for data interpretation, it is still in its infancy and even the most basic questions in this field are still largely unanswered: what kinds of patterns can be extracted from trajectories and which methods and algorithms should be applied to extract them? It is important that investigators be aware of these at the start of the analysis. It is also important to note that many of these still don’t have a single solidified answer or solution, as identified through the literature.
The analysis of spatiotemporal data requires that both temporal correlations and spatial correlations be taken into account. Assessing both the temporal and spatial dimensions of data adds significant complexity to the data analysis process for two major reasons: 1) Continuous and discrete changes of spatial and non-spatial properties of spatiotemporal objects and 2) the influence of collocated neighboring spatiotemporal objects on one another.
A key issue arises when including both space and time in a single model:
Space is two-dimensional and has unlimited directionality: N-S-E-W and everywhere in between while time is unidimensional and can only move in one direction – FORWARD, and thus challenges the way in which we can interpret the result of spatiotemporal analyses.
Another issues arises with how the data is defined and can have strong impact on the patterns discovered. One persistent issue is the Modifiable Areal Unit Problem (MAUP):
The investigator can get completely different answers depending on whether space is assessed by states or zip codes or census tracts, and whether time is assessed by year or day or minute. The same exact analysis can be done by different spatial/temporal definitions and the results can lead to entirely different answers. Therefore, depending on how the investigator defines the data, they may get interesting but spurious patterns
Such problems can impact the interpretability of the analysis. Because we are not looking at two variables with the same directionality, we cannot simply interpret the betas like we are used to and must take this factor into consideration. This is even more complex if you begin to transform your data for analysis. The concepts required to describe the units of analysis may be occurring at higher conceptual levels that are more appropriate for interpretation and policy implications.
Spatiotemporal Data Analysis Workflow
With some of these challenges in mind, we provide a walkthrough on how spatiotemporal analysis is done, using a largely generalized approach.
The goal is to give you enough information to know if you want to begin working with spatiotemporal data, how you could start to assess whether your data is appropriate, and give you resources to further the analysis.
In practice, the two primary goals of spatiotemporal analysis tend to be prediction and description. For simplicity, we will focus on the workflow that would occur as you were doing a descriptive spatiotemporal analysis with a chronic disease focus. However, this approach can branch into a predictive model, for which we provide resources to explore as need.
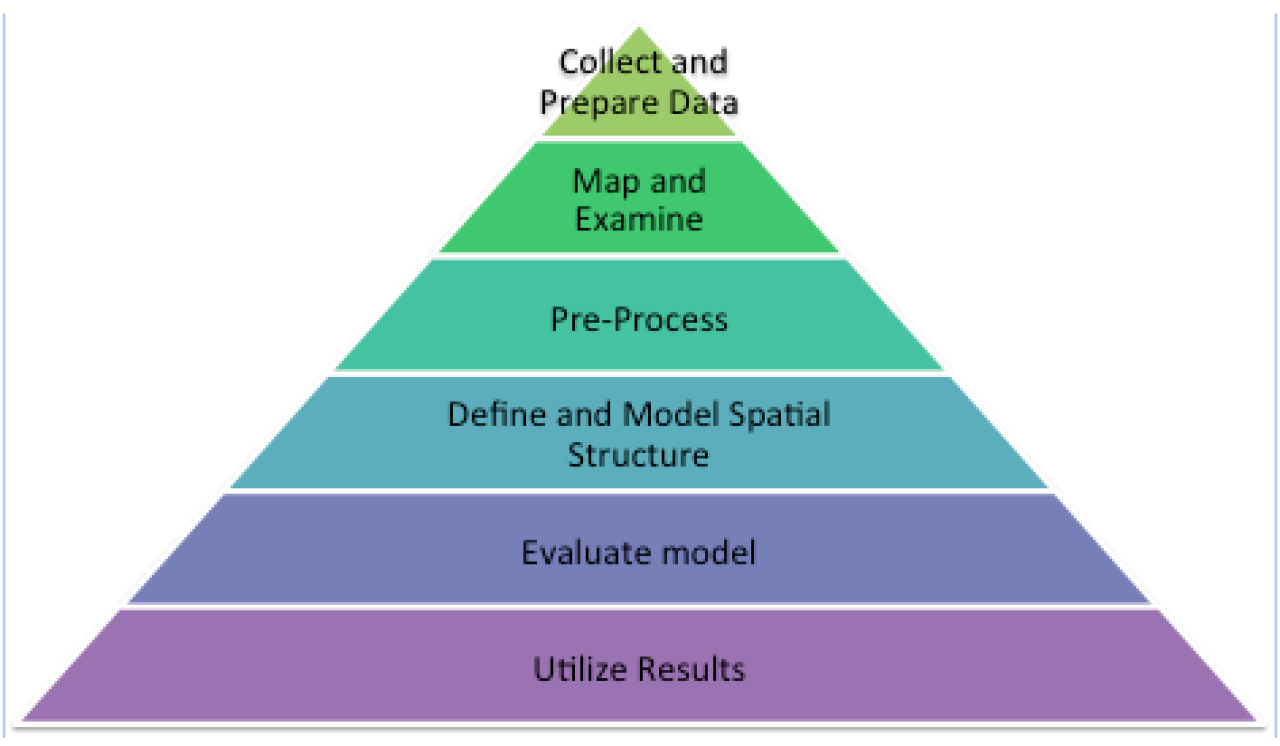
Step 1: Collect and Prepare Data
The key requirement is that all data must be linked to both a spatial and a temporal component. Spatial data can analyze on many levels, zip codes, census tract, state, geocode, etc. Temporal data is often analyzed as multiple data points per observation over time and can be measured by just as many ways as the spatial data, if not more. One can also look at events by year, month, minute, second, but this must also be linked to spatial data.
The plethora of options for how to define your spatial and temporal data is a challenge, particularly when you want to compare your results to other studies or make it applicable to other populations.
If you are collecting your own data, doing research before data collection is important to see how others are defining the problem. If you are fortunate enough to have primary data that you collected, you can define your observations with your analysis in mind. But often, this is not the case and we are analyzing data that we are obtaining from other sources. It is getting more frequent to be able to get information linked to spatial data, which really helps as you are collecting data for your analysis. When doing complex analyses like spatiotemporal analysis you need so many data components and can rarely find all data from only one source. Often you can collect some of the data yourself with your particular analyses in mind and then you can obtain other components from different secondary data sources. More and more databases are including spatial data leading to more and more people with the ability to do these analyses.
Step 2: Map and Examine
Once we have our data, as in all data-driven studies, a key next step is to begin to examine the data. Much like when we run simple frequencies or cross-tabs to explore other forms of data, we do the same general approach with spatiotemporal data. In addition to descriptive data analyses, we can examine our data using simple descriptive maps. By doing this, we can get a clear visualization of important characteristics or trends that may be linked to spatial data that we may not see by just looking at the data. We can also pinpoint outliers, potentially erroneous data, and small or large cell counts that may become problematic.
Example:

Map A Map B
Map A: Breast cancer mortality rates were mapped using clear colors, to see that there may be some clustering around states with lowest rates (green) and highest rates (red). A histogram of rates was also produced to see potential outliers and there is one state (Mississippi) with higher rates than other states (28 deaths per 100,000). Given the findings, you would check to see if these rates are consistent with other years and in other states.
Map B: In this map we are using mortality counts to look at potential small cell counts or erroneous data that may cause issues. We have one large outlier, but further analysis indicates that the state is California, which has a very large population to begin with so it may be less of a concern. The map indicates that there are many small counts in areas with non-concentrated population (i.e, western states, Maine, etc). You may also want to look further into figuring out why – are these low counts because of the low population or is it something else like a data collection issue. In addition to small counts, we can see places of clustering in this map that we wouldn’t be able to see with traditional frequencies. Why are these two clusters here?
Step 3: Pre-Process
Spatiotemporal data may often need to be transformed before analyzing. If necessary, use techniques to center the data and use transformations to make the data fit closely to a normal distribution.
Another key aspect is to test for non-independence of spatially linked observations. Need to be concerned about clustering, and depending on what your data looks like and what clustering you are expecting, you use different methods. Various ways clustering can occur are :
-
Spatial clustering based on non-spatial attribute values of ST objects
-
Clustering of moving objects
-
Density clustering
If clustering is found you may need to transform data using algorithms which extract potential statistical clusters
Often in spatiotemporal data an issue that may lead to bias is the existence of autocorrelation. This stems back to the requirement we discussed earlier of the analytical models that all spatial objects are independent of each other and all temporal data is independent of it.
Spatial Autocorrelation:
Autocorrelation is the mechanism through which subjects living closer together may be more similar than expected giving a truly random spatial distribution. Or, based on our example of breast cancer mortality rates in the US, states closer to each other may be more similar than states that are further away from each other.
In comparison to a traditional correlation, which looks at the relationship between two variables, autocorrelation measures the correlation between a variable X, and the average value of X for neighboring states (countries, zip codes, people). If autocorrelation is due to unmeasured factors that are spatially correlated with your variables of interest, it will introduce bias to the results of the analysis. The presence of autocorrelation violates the independence assumption and your resulting models may have unstable parameter estimates and unreliable p-values for any regression analyses.
The most frequently used method to assess autocorrelation was Morans I value. It is the most general calculation as you can use point data or polygons (like states), and you can also include all data types, whether you have categorical, binary, or continuous variables, so it may be a good start when assessing your data.
Step 4: Define and Model Spatial Structure
There are many models that are housed within the spatiotemporal framework and that can be used for these types of analyses. We found that saying ‘spatiotemporal analysis’ was almost as broad as saying ‘regression’ which makes it simultaneously easy to analyze your data in these methods because you can fit many models and it is difficult to analyze because there is rarely a clear cut method to use.
Following are a few methods that are frequently used in the literature:
Conditional Autoregression:
Autoregression is often used in longitudinal or time series data, and models the outcome variable as it depends linearly on it’s own previous values. It best accounts for local effects, so if you expect to see a lot of within spatial variability (differences across individuals) this may be an effective method.
Space-Time Autoregressive Integrated Moving Average:
Not only does the outcome depend on its previous values over time, but also its previous values in space. Often used for data with large distances between space and time points and very large datasets
Spatial Multivariate Age-Period-Cohort (APC) Effects:
Takes into consideration APC effects as well as differential geographical effects on behavior. Often used in cancer models to assess relationships of where people live, how that effects their behavior, in addition to classic APC effects we see in cancer.
P-spline models:
Provides smoothed parameter estimates along space and time on a large, global scale. The smoothing is carried out in three dimensions (longitude, latitude, and time). This can be useful if you expect significant changes at different time points. For example, this method can be used if you wanted to see the effects of health care on a disease outcome across states before and after Affordable Health Care Act.
Step 5: Evaluate Model
To evaluate the quality of the model, the analyst then examines the model residuals.
The temporal distribution of the residuals is explored by means of the time graph display and the spatial distribution by means of the map display. A model is considered correctly generated or captures the general features of spatiotemporal variation when there is an absence of clear temporal and spatial patterns, or in other words, the distributions for each dimension appear as random noise.
If random distribution is not established the analyst may choose to modify the model or segment the group and revise the analysis. Other key factors to consider in the evaluation step is to look at the key assumptions of the theoretical ST model – all temporal structures should be captured by the smooth temporal basis function and the spatial dependencies should demonstrate stationarity.
Step 6: Utilize Results
The last task in analytic approach with spatiotemporal data analysis it to utilize the results.
Once the model has been satisfactorily built, adjusted and output checked, the results can be used in risk analyses and decision-making. Interpretation of the results depends on whether the model is built to describe novel patterns in health mapping or whether the model was developed to predict future disease outcome patterns.
Since we only described general steps taken to develop a spatiotemporal model for descriptive cases, an example of how results are interpreted can be examined in a 2010 study looking at the Age-Specific Spatiotemporal Patterns of Female Breast Cancer Mortality in Spain from 1975-2005 – See references.
Utility and Future Direction
The rapid growth of spatiotemporal datasets due to widespread collection of network and location-aware decides has raised the demand in spatiotemporal data analytic approaches. These huge collections of spatiotemporal data often hide possibly interesting information and valuable knowledge. Spatiotemporal analysis poses many challenges but it’s a promising application for various disciplines and research questions.
It’s important to keep in mind that this is still a largely underexplored research area but future work will involve developing detailed requirement analysis and development techniques for each of the spatiotemporal data mining task, evaluation of techniques with large datasets in different domains at multiple spatial and temporal granularities, identifying quality measures specific for each of the ST data mining task and growth of this technique in our field will depend on interdisciplinary collaboration of data minders with researchers in different disciplines to evaluate the method and how discovered results are interpreted.
Readings
Textbooks & Chapters
Applied Spatial Statistics for Public Health Data
Lance A. Waller & Carol A. Gotway
John Wiley & Sons, Incorporated / 2004
http://site.ebrary.com.ezproxy.cul.columbia.edu/lib/columbia/detail.action?docID=10114139
Encyclopedia of GIS
Shashi Shekhar & Hui Xiong
Springer / 2008
http://link.springer.com.ezproxy.cul.columbia.edu/referencework/10.1007%2F978-0-387-35973-1
Statistical Analysis of Spatial and Spatio-Temporal Point Patterns, Third Edition
Peter J. Diggle
Chapman and Hall / 2013
http://www.crcnetbase.com.ezproxy.cul.columbia.edu/isbn/9781466560246
Displaying Time Series, Spatial, and Space-Time Data with R
Oscar Perpinan Lamiguerio
Chapman and Hall/ 2014
http://www.crcnetbase.com.ezproxy.cul.columbia.edu/isbn/9781466565227
Methodological Articles
Background Information
Meliker, J. R., & Sloan, C. D. (2011). Spatio-temporal epidemiology: principles and opportunities.Spatial and Spatio-Temporal Epidemiology, 2(1), 1–9.
Review paper discussing the basic concepts and utilization of spatio-temporal analysis in epidemiology.
Nobre F. F., & Sa Carvalho M. Spatial and Temporal Analysis of Epidemiological Data http://epi.minsal.cl/SigEpi/doc/GISSpatial.htm
Basic Introduction to the topic and what it can be used for in epidemiology.
Roddick, J. F., Hornsby, K., & Spiliopoulou, M. (2001). An Updated Bibliography of Temporal, Spatial, and Spatio-temporal Data Mining Research. Temporal, Spatial, and Spatio-Data Mining Lecture Notes in Computer Science, 2007, 147–163.
Basic introduction to spatio-temporal analysis and data mining along with an extensive list of resources and journal articles referring to the topic.
Application Articles
Andrienko, N., & Andrienko, G. (2012). A visual analytics framework for spatio-temporal analysis and modelling. Data Mining and Knowledge Discovery.
Combines traditional spatio-temporal analyses with visual techniques to analyze spatially referenced time series data. Discusses model selection, adjustment of model parameters, and model evaluation.
Chen, Q., Han, R., Ye, F., & Li, W. (2011). Spatio-temporal ecological models. Ecological Informatics, 6(1), 37–43.
Introduction of a systems dynamic model to address spatio-temporal changes in a population.
Fang, X., & Chan, K.-S. (2014). Additive models with spatio-temporal data. Environmental and Ecological Statistics, 22(1), 61–86.
Proposes a new approach to using additive models (AM) with correlated data, particularly spatio-temporal data, based on a penalized likelihood method. Also discusses methods of model selection criteria in data with and without spatial correlation using an example data analysis.
Joon Y. Park. The Spatial Analysis of Time Series
http://www.ruf.rice.edu/~econ/papers/2005papers/park07.pdf
In-depth information on theory behind the framework of spatio-temporal analyses.
Kamarianakis, Y. Spatial-time series modeling: A review of the proposed methodologies.
http://www.iacm.forth.gr/papers/spatial_time_series_overview.pdf
Review of basic methodologies for spatial-temporal data with corresponding real life data examples. Focus on Space-Time ARIMA (STARIMA), Bayesian Vector Autoregressive Model (BVAR), and Spatial Autoregressive Distributed Lag Models.
Law, J., Quick, M., & Chan, P. (2013). Bayesian Spatio-Temporal Modeling for Analysing Local Patterns of Crime Over Time at the Small-Area Level. Journal of Quantitative Criminology, 30(1), 57–78.
Developed a method to apply Bayesian spatio-temporal modeling to crime trend analysis, particularly in a small-area level. Discusses past methods used to date and benefits of the Bayesian model.
MacNab, Y. C., & Dean, C. B. (2002). Spatio-temporal modelling of rates for the construction of disease maps. Statistics in Medicine, 21(3), 347–58.
Focuses on numerous methods behind disease mapping with focus on disease incidence and mortality over both space and time. In an example, the article uses generalized additive mixed models to look at infant mortality in Canada over time.
Papoila, A. L., Riebler, A., Amaral-Turkman, A., São-João, R., Ribeiro, C., Geraldes, C., & Miranda, A. (2014). Stomach cancer incidence in Southern Portugal 1998-2006: a spatio-temporal analysis. Biometrical Journal. Biometrische Zeitschrift, 56(3), 403–15.
Cancer mortality is analyzed using a spatial multivariate age-period-cohort model in order to avoid age aggregation and allow analysis of time trends between males and females across age, period, birth cohort, and space.
Ruiz-Medina, M. D., Espejo, R. M., Ugarte, M. D., & Militino, A. F. (2013). Functional time series analysis of spatio–temporal epidemiological data. Stochastic Environmental Research and Risk Assessment, 28(4), 943–954
Paper discusses the use of the autoregressive Hilbertian process framework to estimate the temporal change of mortality relative risk maps. The method is illustrated in an analysis of breast cancer mortality in Spain from 1975-2005. The authors then use simulated data to compare this approach to the classic spatio-temporal CAR approach and discuss differences.
Spatio-Temporal Modeling
http://www.stat.unc.edu/faculty/rs/s321/spatemp.pdf
Great overview to many models available for spatio-temporal analysis.
Ugarte, M. D., Goicoa, T., Etxeberria, J., Militino, A. F., & Pollán, M. (2010). Age-Specific Spatio-Temporal Patterns of Female Breast Cancer Mortality in Spain (1975–2005). Annals of Epidemiology, 20(12), 906–916.
Uses P-spline models to look at breast cancer mortality across Europe and Spain from 1975-2005. Addresses spatio-temporal smoothing of mortality risks across three dimensions: longitude, latitude, and time.
Wall, MM. (2004). A close look at the spatial structure implied by the CAR and SAR models. Journal of Statistical Planning and Inference, 121, 311-324.
http://www.esg.montana.edu/biol504/wall04.pdf
Describes and compares the statistical and correlational structures of Conditional Autoregressive (CAR) and Simultaneously Autoregressive (SAR) models. The paper then discusses the practical uses of each of these models and gives an example analysis comparing the two spatial models.
Software
R
Download R (FREE)
http://www.r-project.org/
Handling and Analyzing Spatio-Temporal Data
http://cran.r-project.org/web/views/SpatioTemporal.html
Vast list of packages available for the collection, analysis, and mapping of spatio-temporal data in R.
ArcGIS
Esri’s ArcGIS is effective in creating maps, compiling geographic data, and disseminating visually appealing spatio-temporal results. Is not as user friendly for running complex analytical tasks.
Free ArcGIS Online
https://www.arcgis.com/home/
Create basic maps that can be used in an online format
ArcGIS 60 day free trial
http://www.arcgis.com/features/free-trial.html
ArcGIS Help Page
http://resources.arcgis.com/en/help/
Websites
GeoData @ Columbia
http://culspatial.cul.columbia.edu/
Columbia University Digital Social Science Center
http://library.columbia.edu/locations/dssc/data.html
Census
www.census.gov
https://www.census.gov/geo/maps-data/data/tiger-cart-boundary.html
NYC GIS Clearinghouse
https://gis.ny.gov/gisdata/
EPA Environmental Data
http://www.epa.gov/reg3esd1/data/gis.htm
Open Data ArcGIS
http://opendata.arcgis.com/
The National Map
http://nationalmap.gov/
Courses
ESRI Training (ArcGIS)
Beyond Where: Using regression Analysis to Explain Why
http://training.esri.com/gateway/index.cfm?fa=catalog.webCourseDetail&courseid=2586
Working with Temporal Data in ArcGIS
http://video.esri.com/watch/93/working-with-temporal-data-in-arcgis
True Spatial-Temporal Data Analysis Using ArcGIS and R Statistical Computing Language
http://video.esri.com/watch/3373/true-spatial_dash_temporal-data-analysis-using-arcgis-_and_-r-statistical-computing-language
University of Washington Center for Studies in Demography and Ecology
Online GIS Workshop and Lab. Includes presentations, lab materials, data.
Exploratory Spatial Data Analysis
https://csde.washington.edu/services/gis/workshops/ESDA.shtml
Spatial Regression
https://csde.washington.edu/services/gis/workshops/SPREG.shtml