Meta-Analyses of Aggregate Data or Individual Participant Data Meta-Analyses (Retrospectively and Prospectively Pooled Analyses)
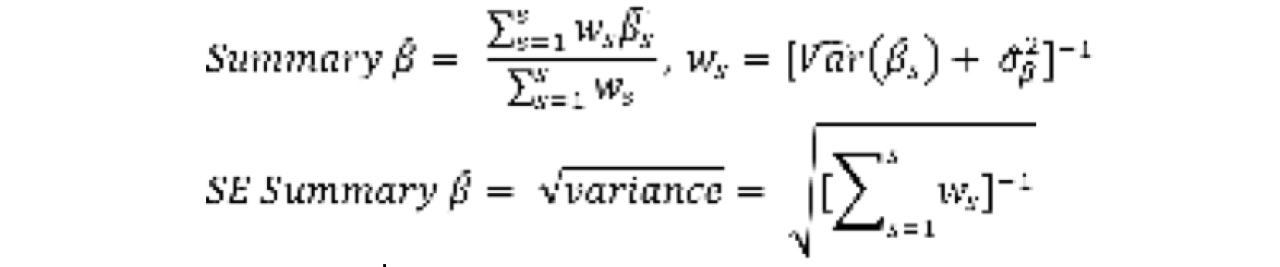
| Overview | Software |
| Description | Websites |
| Readings | Courses |
Overview
The purpose of this page is to describe and compare and contrast three quantitative approaches—meta-analyses of aggregate data, meta-analyses of individual participant data (retrospective pooled studies), and prospectively planned pooled studies—and provide resources to support the adoption of these methods.
Description
The purpose of summarizing evidence across studies is to assess and investigate whether there is consistent or inconsistent evidence supporting specific exposure-outcome relationships and to examine sources of heterogeneity in studies that might yield differences in findings (Blettner et al. 1999). Qualitative reviews such as non-systematic narrative reviews and systematic reviews provide non-statistical overviews of the literature. Quantitative methods synthesize information across studies using statistical methods to generate summary estimates that generalize the findings of the individual studies. The three primary quantitative methods of information synthesis include meta-analysis of aggregate data, meta-analysis of individual participant data (retrospective pooled studies), and prospectively planned pooled studies.
Meta-Analysis of Aggregate Data
Purpose: A meta-analysis of aggregate data (AD) uses statistical analyses to generate a summary (pooled) estimate using effect estimates of individual studies reported in the published literature.
This type of review is the most commonly used of the three quantitative approaches because it can be completed relatively quickly, it is low-cost, and the data it uses (information from published, full-text articles) is relatively easy to access (Blettner et al. 1999). Despite these advantages, meta-analyses of AD are subject to the effects of publication bias. Additionally, researchers conducting the meta-analysis have very limited control over the data and have to interpret summary effects within the context of the heterogeneity that arises between the various study designs, model selections, analysis approaches, and variable categorizations of the original studies.
Steps of a Meta-Analysis of Aggregate Data:
1. Conduct a systematic review of the literature:
The first step in conducting a meta-analysis of AD is to conduct a systematic review. A systematic review is primarily focused on identifying all of the available, relevant studies that are related to a specific and well-defined question of interest. To achieve this comprehensive review, investigators identify specific search terms, utilize multiple databases, and establish well-defined inclusion and exclusion criteria to identify a final pool of relevant studies.
2. Extract data from published papers:
Once the final pool of relevant studies is identified, data must be extracted from the published literature. It is important to note that each study should only be represented once in the analysis, even though information for the study may be published over several papers (Higgins and Green, 2011). The effect estimate and variance should be extracted to calculate the summary estimate (Higgins and Deeks, 2011). The exposure, outcome and covariates used in the models and how they were defined (e.g., continuous, categorical with cut points for categories) and study characteristics, (e.g., study design, sample size, sample demographics, year of publication) should be extracted to assess study heterogeneity (Higgins and Deeks, 2011). Some information may not be available from the published literature and it is advisable for
3. Convert individual study estimates to a common scale:
Investigators often do not take identical approaches to study design or data analysis. As such, studies may report different effect measures, such as odds ratios, risk ratios, and hazard ratios. If this is the case, it may be necessary to convert the extracted effect estimates to a single type of effect estimate so that they may be compared and combined to generate the summary estimate.
4. Report individual study estimates:
It is necessary (and helpful) to visualize the individual study estimates and confidence intervals in a forest plot. This allows the researcher and reader to visualize any general trends or mixed findings across the studies.
5. Estimate a summary estimate using weighted averages of individual study estimates:
Studies included in a meta-analysis often vary in size, quality, and other characteristics. When generating the summary estimate, it is necessary and important to weight the effect estimates of each study to account for this heterogeneity. Two approaches to weighting—fixed effects and random effects—may be taken.
5a. Fixed effects:
The underlying assumption in a fixed-effects approach is that all studies included in the meta-analysis are estimating the same, underlying “true” effect (Borenstein et al. 2007). Variability (error) is assumed to originate from within each study, not between the studies. The model statement for the fixed effect approach looks like this:
β̂s = β + εs , s = 1 to S studies
β = true common effect estimate (e.g., log relative risk)
εs = within study variance
β̂s = estimated effect estimate in study s
Under a fixed effects approach, the inverse-variance method for weighting studies is used. Studies are weighted by the inverse of the study-specific variance and the summary estimate is calculated as a weighted mean of the individual estimates, as shown in this formula:

Because studies are only weighted by the variance between individuals within a study, smaller studies, which are generally expected to be less precise (i.e., have larger variance because there are fewer data points), will be weighted less and larger studies will be weighted more (Borenstein et al. 2007):
5b. Random effects:
In a random effects approach, the assumption is that there is no true effect estimate, but rather a normal distribution of effects (Borenstein et al. 2007). Variability is thought to arise from both within and between study variance. The model statement for a random effects model is written like this:
β̂s = β + Us + εs , s = 1 to S studies
β = mean true effect estimate (e.g., log relative risk)
εs = within study variance
Us = between study variance
β̂s = estimated effect estimate in study s
Under a random effects approach, the DerSimonian and Laird Model to weighting studies is used. When calculating the pooled estimates, individual study estimates are weighted by taking into account both within and between variance, as shown in this formula:
A random effects approach to deriving the summary estimate means the weights are more balanced (i.e., small studies are not trivialized as much and large studies are not weighted as heavily) (Borenstein et al. 2007). The trade-off for this approach is precision in the summary confidence intervals; generally, summary estimates using random effects models yield larger pooled variances and confidence intervals than the fixed effect approach (Borenstein et al. 2007).
6. Assess and identify sources of heterogeneity:
Aside from generating the summary estimate, the other major goal of a meta-analysis of AD is the assessment and identification of study heterogeneity. Study heterogeneity arises from systematic differences between studies that may arise from factors such as study design or sample characteristics. The two primary heterogeneity statistics are the Cochran’s Q statistic and the Inconsistency Index. In short, Cochran’s Q Statistic (χ2 test of heterogeneity, df = k-1) is a weighted sum of the squared deviations (Borenstein et al. 2007). It has poor power to detect heterogeneity among a small number of studies. The Inconsistency Index (I2) is the percentage of total variation across studies that is due to heterogeneity (Higgins et al., 2003). The I2 is less influenced by the number of studies included in meta-analysis and can be compared across meta-analyses.
When either of these measures of heterogeneity are high, summary estimates should be interpreted with caution. High levels of heterogeneity may warrant that the meta-analysis should not move forward or that studies should be divided and separate subgroup summary estimates should be derived (Deeks et al. 2011). Additional investigation of the sources of heterogeneity should be undertaken. In meta-analyses of AD, sensitivity analyses to investigate heterogeneity focus on study characteristics. Investigators may stratify by study characteristics (e.g., study design) or they may exclude studies with a particular characteristic and recalculate the summary estimate, reporting differences between the original and new estimate (Deekset al. 2011). Meta-regression may also be used to investigate heterogeneity due to study-level variables.
In meta-analysis of AD, publication bias should be assessed. Publication bias occurs when a greater percentage of studies suggesting beneficial or large effects are published, but fewer studies reporting null effects, negative effects or smaller studies are published (Sterne et al. 2011). If there is publication bias, then a meta-analysis of AD will report a summary effect that only reflects effects found in published studies and will not reflect the “true” effect or distribution of true effects in a population
Reporting
At present, the PRISMA Statement is a widely used and accepted guideline for conducting and reporting systematic reviews and meta-analyses. The PRISMA Statement includes a checklist of items that should be executed and reported as part of a meta-analysis and it also includes a flow diagram which allows readers to follow the selection and elimination process of the articles that are included in the meta-analysis (Liberati et al. 2009).
Individual Participant Data (IPD) Meta-Analysis (Pooled Analyses)
Purpose: The individual participant data (IPD) meta-analysis, also known as a retrospective pooled analysis, uses statistical analyses to generate a summary estimate using individual participant data from published and unpublished studies.
IPD meta-analyses take more time to complete (several years), cost significantly more (to cover cost of personnel, data housing, data cleaning and harmonization), and can face more challenges in obtaining the data (original study investigators must agree to share original data) than meta-analyses of AD (Cooper and Patall, 2009; Riley et al. 2010). Despite these challenges, researchers are rewarded with increased control over the data and analysis which allows them to reduce some of the between study heterogeneity that results from exclusion criteria, covariate selection, and analysis selection (Stewart and Tierney, 2002). Further, the use of individual data allows researchers to pose new questions that may not have been the goal of the original studies and increases the statistical power to investigate rare diseases and exposures.
Steps of an IPD Meta-Analysis:
1. Conduct a systematic review of the literature, identify unpublished studies, and obtain individual level data from original investigators.
Like a meta-analysis of AD, an IPD meta-analysis begins with a systematic review and utilizes methods such as key word selection and a priori inclusion and exclusion criteria to identify a pool of eligible studies (Blettner et al. 1999; Stewart et al. 2015). Additionally, researchers contact investigators in the field to identify any unpublished studies that may be eligible to be included in the meta-analysis (Stewart et al. 2015). Once the final pool of studies has been identified, investigators are contacted to obtain the original data. This requires relationship building, clearly stated goals of the meta-analysis, cooperation and trust to facilitate the sharing of data and ongoing clarification about study methods throughout the data harmonization process. A collaboration between investigators is often formed to conduct the meta-analysis (Stewart et al. 2011). IPD meta-analyses also require significant funds and a means to securely store and clean data. Near the conclusion of this entry, a brief note is made to discuss ethical concerns when working with individual level data.
2. Harmonize data
The goal of data harmonization is to maximize comparability between studies by reducing heterogeneity that arises from different assessments/categorizations of variables. In meta-analyses of AD, researchers are limited to variable specifications published in the manuscripts. In IPD meta-analyses, researchers have access to the original data and may be able to use the same original measures across a range a studies (e.g., BMI rather than categorical obese/not obese). In other cases, measures may not be the same across all variables, but a common categorization across studies may be possible (e.g., high depressive symptoms vs. low depressive symptoms if different scales of depressive symptoms are used) (Stewart and Tierney, 2002). In some cases, data harmonization is not possible, particularly when the original investigators used different measures (e.g., diet assessed through 3-day recall, country/group-specific food frequency questionnaire).
3. Pool studies to calculate a summary estimate
Once data has been harmonized, researchers may wish to apply additional exclusion criteria to the individual-level data. These exclusions should be applied to observations across all studies (Stewart and Tierney, 2002).
When researchers are ready to pool the data, two approaches may be taken—the one-step approach and the two-step approach. The two-step approach is most familiar because it closely resembles the methodology of a meta-analysis of AD, but it can be more time consuming than the one-step approach. Still, the two-step approach is likely a good first step to take in an IPD meta-analysis because it gives the researcher an idea of the trend of estimates across individual studies before obtaining a pooled estimate.
3a. The two-step approach
The two-step approach in an IPD analysis is similar to the meta-analysis of aggregate data. First, the each individual study estimate is calculated (rather than extracted from the published literature). These individual estimates are plotted using a forest plot and compared to observe any similarities and differences. The same statistical analysis, covariate inclusion, definition of exposures and outcomes are used when calculating each individual study estimate. Next, individual estimates are weighted and pooled using fixed or random effects methods, as described above
3b. The one-step approach
In the one-step approach, the individual data points from all of the studies are fitted together in a single model or set of analyses, rather than calculating estimates for each study individually. When fitting the model, accounting for clustering must occur or else investigators risk finding significant effects when there are none, or vice versa (Abo-Zaid et al. 2013). A fixed effect approach (e.g. using dummy variables for clusters) may be used, or hierarchical or mixed-effect regression models can be used to incorporate random effects (both for slopes and intercepts) into the model.
In general, the one-step approach will produce summary effects similar to the two-step approach, with the exception of when there is binary outcome data (Stewart et al. 2012). Even if summary effects are similar, the one-step approach might offer additional flexibility that make it useful for incorporating more complex statistical methods used in single-study analyses. First, one-step approaches allow researchers to focus on the within study (between individual) differences in effects, adjusting for clustering through either fixed effect or random effect models. Second, the one-step approach allows researchers to compare a number of different models with different assumptions or compare nested models using model fit measures such as AIC (Stewart et al. 2012). While this may also be accomplished in a two-step approach, each new model must be calculated for each individual study before pooling, which can be time consuming. Third, the one-step approach may preferable to addressing questions using longitudinal data (Jones et al. 2009). In the one-step approach, researchers can account for the correlation of repeated observations in the analysis, rather than losing that information in the pooling step of the two-step approach. This is expected to yield more appropriate standard errors for the pooled estimate. Lastly, the one-step approach may offer more flexibility to investigate interactions than the two-step approach, allowing for the fitting of non-linear covariates, for example (Stewart et al. 2012; Cooper and Patall, 2009).
While the one-step approach allows for increased model complexity and non-linearity of exposures and covariates, models can also be more difficult to interpret and may require additional statistical expertise (Riley et al. 2010). Further, an important assumption of the one-step approach is that variables are measured in a comparable way in all studies (Smith-Warner et al. 2006).
4. Assess and identify sources of heterogeneity
Assessing model heterogeneity in an IPD meta-analysis is just as important as in meta-analysis of AD. In an IPD meta-analysis, heterogeneity is reduced through data harmonization, selection of the same effect measure (e.g., RR, HR) and selection of the same covariates. Even after this, there may be some meaningful differences between studies and this should be assessed using Cochran’s Q test statistic.
Sensitivity analyses are also completed for IPD meta-analyses. Rather than focus on study-level approaches (e.g., separating findings by study design), they can focus on investigations more commonly seen in single-study analyses, such as changing categorizations of variables, inclusion or exclusion of covariates, and subgroup analyses (e.g., race or sex). In the case where some individual data was not attainable, a sensitivity analysis combining published results and the results of the IPD might be conducted (Stewart and Tierney, 2002). Other sensitivity analyses might include comparison of summary estimates derived from one or two-step approaches and analyses using fixed or random effects.
Reporting
In 2015, a Special Communication in JAMA was released regarding the development of PRISMA-IPD Statement. This report provides some updates to the PRISMA Statement that specifically address unique characteristics of IPD meta-analyses (Stewart et al. 2015).
Prospectively Planned Pooled Analyses
Purpose: Similar to IPD meta-analyses/retrospective pooled analyses, prospectively planned pooled analyses aim to pool individual participant data across individual studies. However, instead of reviewing the existing literature and contacting investigators to identify all available existing studies, the process of prospectively pooled analyses involves the creation of inclusive collaborative groups to plan future studies.
Prospectively planned pooled analyses take the longest to complete (several years) of the three methods and are more costly to complete than meta-analyses of AD. Despite added costs of time and money, they offer the advantage of having additional control over study design and data measurement than IPD meta-analyses because they are prospectively planned.
Steps in Conducting Prospectively Planned Pooled Analyses
The steps in conducting a prospectively planned pooled analysis are the same as those outlined above for IPD meta-analysis and are not further detailed here. Instead two notable differences are described.
1. Rather than starting with a systematic review of the literature, prospectively planned pooled analyses begin with discussion between investigators to form a collaborative group. The collaboration is designed to be as inclusive as possible and often includes research centers from several countries. While the rewards of participating in the collaboration are great, a significant amount of time and money is needed to handle the logistics of the collaboration. Logistics include identifying who will be the secretary who oversees the collaboration, the center that will securely store data, and data cleaning responsibilities (Stewart et al. 2011). Additionally, final reporting and publication will need to be discussed and often individual studies may be restricted from publishing their unique study findings until the collaborative study results have been published.
2. Data standardization, rather than data harmonization is one of the major goals in the planning process. Data standardization aims to establish a uniform way in which variables will be defined, measured, and collected. The process of standardization may be easy when there is a gold standard, but may require further discussion and compromise if there are several measures to assess a variable. Differences in approach to variable measurement might vary from country to country or between research centers.
Even though variables of interest are standardized across studies, prospectively planned pooled analyses are not the same as multi-center trials. Centers involved in the pooled analyses are expected to adhere to the same standardized variable measures and some key inclusion criteria for participants, but are allowed to differ in many other regards (e.g., population, country, other variables collected) and are not expected to follow a single study protocol across all sites (Riley et al. 2010).
Note: Ethical concerns when working with individual level data
Unlike meta-analyses of AD, IPD meta-analyses and prospectively planned pooled analyses must take on additional consideration of participant privacy and confidentiality. Any analyses that utilize participant level data must ensure that the data can be stored and accessed in a secure fashion. This requires that one of the institutions within the collaboration must take responsibility for storing and hosting this information. Because many of these collaborations are international in nature, this data storage must meet the security and confidentiality needs of all researchers’ participating countries (Ragin and Taioli, 2008). In the case of prospectively planned pooled analyses, these considerations can be taken into account from the beginning and should be incorporated into planned costs for the project, protocols submitted to human research review boards at each participating institution, and documents of informed consent for participants.
In the case of retrospective pooled analyses, data collection may already be complete. In the process of obtaining the original data, investigators conducting the secondary data analysis must also verify that the original studies had approved human subject protocols. Additionally, it is recognized that study participants likely consented for the original research study, but may not have consented to participate in a secondary study with potentially different research questions. In the U.S., secondary data analysis is permissible as long as the protocol has received IRB approval and is de-identified (Philips et al. 2013). This process differs from country to country (Philips et al. 2013) and should be investigated prior to moving forward with the meta-analysis of IPD.
Summary of Comparisons of Approaches
A brief table comparing the three quantitative approaches to summarizing evidence across studies is provided for quick reference.
|
Meta-Analysis of AD |
IPD Meta-Analysis/Retrospective Pooled Analysis |
Prospectively Planned Pooled Analysis |
|
|
Length of Time to Complete |
Short |
Long |
Long |
|
Expense |
Low |
High |
High |
|
Control over Data |
Low |
High |
Highest |
|
Concern for Publication Bias |
High |
N/A |
N/A |
|
Collaboration and Cooperation with Other Researchers |
None |
Yes |
Yes |
|
Control over Models |
Low |
High |
High |
|
Additional Ethical Concerns |
None |
Yes |
Yes |
|
Ability to Investigate Rare Diseases and Uncommon Exposures |
Low |
High |
High |
|
Ability to Analyze Longitudinal Data |
Low |
High |
High |
|
Assessing Interactions |
Low |
High (esp. 1-step approach) |
High (esp. 1-step approach) |
References
Abo-Zaid, G, Guo, B, Deeks, JJ, Debray, TPA, Steyerberg, EW, Moons, KGM, and Riley, RD (2013) Individual participant data meta-analyses should not ignore clustering. J Clin Epidemiol; 66(8): 865-873.
Blettner, M, Sauerbrei, W, Schlehofer, B, Scheuchenpflug, T, and Friedenreich, C. (1999) Traditional reviews, meta-analyses and pooled analyses in epidemiology. International Journal of Epidemiology; 28: 1-9.
Borenstein, M, Hedges, L and Rothstein, H (2009) Fixed effects vs. random effects models. In: Introduction to Meta-Analysis. Eds: Borenstein, M, Hedges, LV, Higgins, JPT, and Rothstein, HR. John Wiley & Sons, Ltd., West Sussex, UK.
Cooper, H and Patall, EA (2009) The relative benefits of meta-analysis conducted with individual participant data versus aggregated data. Psychological Methods; 14(2), 165-176.
Deeks, JJ, Higgins, JPT and Altman, DG (2011) Chapter 9: Analysing data and undertaking meta-analyses. Cochrane Handbook for Systematic Reviews of Interventions. Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Higgins JPT, Green S (editors). Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. The Cochrane Collaboration, 2011. Available from www.cochrane-handbook.org.
Higgins, JPT, Thompson, SG, Deeks, JJ, and Altman, DG. (2003) Measuring inconsistency in meta-analyses. BMJ; 327(7414): 557-560.
Higgins, JPT and Deeks, JJ (2011) Chapter 7: Selecting studies and collecting data. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Jones, AP, Riley, RD, Williamson, PR, and Whitehead, A (2009) Meta-analysis of individual patient data versus aggregate data from longitudinal clinical trials. Clinical Trials; 6: 16-27.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gøtzsche P, et al. (2009) The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. PLoS Med 6: e1000100. doi:10.1371/journal.pmed.1000100.
Philips B, Ranasinghe, N, Stewart, LA and the PICNICC Collaboration (2013) Ethical and regulatory considerations in the use of individual participant data for studies of disease prediction. Arch Dis Child; 98: 567-568.
Ragin, C and Taioli, E (2008) Meta-analysis and pooled analysis – Genetic and environmental data. In: Molecular Epidemiology of Chronic Diseases; CP Wild, P Vineis, and S Garte. John Wiley & Sons.
Riley, RD, Lambert, PC, and Abo-Zaid, G (2010) Meta-analysis of individual participant data: rationale, conduct and reporting. BMJ; 340; c221.
Smith-Warner, SA, Spiegelman, D, Ritz, J, et al. (2006) Methods for pooling results of epidemiologic studies: The Pooling Project of Prospective Studies of Diet and Cancer. Am J Epidemiol; 163: 1053-1064.
Sterne, JAC, Egger, M, and Moher, D (2011) Chapter 10: Addressing reporting biases. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Stewart, GB, Altman, DG, Askie, LM, Duley, L, Simmonds, MC, and Stewart, LA. (2012) Statistical analysis of individual participant data meta-analyses: A comparison of methods and recommendations for practice. PLoS ONE; 7(10): e46042.
Stewart, LA, Clark, M, Rovers, M, Riley, RD, Simmonds, M, Stewart, G, Tierney JF and The PRISMA-IPD Development Group (2015) Preferred reporting items for a systematic review and meta-analysis of individual participant data: The PRISMA-IPD Statement. JAMA; 313(16): 1-1665.
Stewart, LA and Tierney, JF (2002) To IPD or not to IPD? Advantages and disadvantages of systematic reviews using individual patient data. Evaluation & The Health Professions; 25(1): 76-97.
Stewart, LA, Tierney, JF, and Clarke, M (2011) Chapter 18: Reviews of individual patient data. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Readings
Systematic review
Higgins JPT, Green S (editors). Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. The Cochrane Collaboration, 2011. Available from www.cochrane-handbook.org.
Meta-analysis of aggregate data
Borenstein, M, Hedges, LV, Higgins, JPT, and Rothstein, HR (2009) Chapter 7: Converting Among Effect Sizes. In: Introduction to Meta-Analysis. Eds: Borenstein, M, Hedges, LV, Higgins, JPT, and Rothstein, HR. John Wiley & Sons, Ltd., West Sussex, UK.
Borenstein, M, Hedges, L and Rothstein, H (2007) Fixed effects vs. random effects models. In: Introduction to Meta-Analysis. Eds: Borenstein, M, Hedges, LV, Higgins, JPT, and Rothstein, HR. John Wiley & Sons, Ltd., West Sussex, UK.
Deeks, JJ, Higgins, JPT and Altman, DG (2011) Chapter 9: Analysing data and undertaking meta-analyses. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Higgins, JPT and Deeks, JJ (2011) Chapter 7: Selecting studies and collecting data. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Higgins, JPT, Thompson, SG, Deeks, JJ, and Altman, DG. (2003) Measuring inconsistency in meta-analyses. BMJ. 327(7414): 557-560.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gøtzsche P, et al. (2009) The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: Explanation and elaboration. PLoS Med 6: e1000100. doi:10.1371/journal.pmed.1000100.
Meta-analysis of individual data (retrospective pooled analysis) and prospectively planned pooled analysis
Abo-Zaid, G, Guo, B, Deeks, JJ, Debray, TPA, Steyerberg, EW, Moons, KGM, and Riley, RD (2013) Individual participant data meta-analyses should not ignore clustering. J Clin Epidemiol; 66(8): 865-873.
Cooper R, Hardy R, Aihie Sayer A, Ben-Shlomo Y, Birnie K, Cooper C, et al. (2011) Age and Gender Differences in Physical Capability Levels from Mid-Life Onwards: The Harmonisation and Meta-Analysis of Data from Eight UK Cohort Studies. PLoS ONE 6(11): e27899. doi:10.1371/journal.pone.0027899
Philips B, Ranasinghe, N, Stewart, LA and the PICNICC Collaboration (2013) Ethical and regulatory considerations in the use of individual participant data for studies of disease prediction. Arch Dis Child; 98: 567-568.
Riley, RD, Lambert, PC, and Abo-Zaid, G (2010) Meta-analysis of individual participant data: rationale, conduct and reporting. BMJ; 340; c221.
Riley, RD and Steyerberg, EW (2010) Meta-analysis of binary outcome using individual participant data and aggregate data. Research Synthesis Methods; 1(1): 2-19.
Smith-Warner, SA, Spiegelman, D, Ritz, J, et al. (2006) Methods for pooling results of epidemiologic studies: The Pooling Project of Prospective Studies of Diet and Cancer. Am J Epidemiol; 163: 1053-1064.
Stewart, GB, Altman, DG, Askie, LM, Duley, L, Simmonds, MC, and Stewart, LA. (2012) Statistical analysis of individual participant data meta-analyses: A comparison of methods and recommendations for practice. PLoS ONE; 7(10): e46042.
Stewart, LA, Clark, M, Rovers, M, Riley, RD, Simmonds, M, Stewart, G, Tierney JF and The PRISMA-IPD Development Group (2015) Preferred reporting items for a systematic review and meta-analysis of individual participant data: The PRISMA-IPD Statement. JAMA; 313(16): 1-1665.
Comparisons of approaches
Blettner, M, Sauerbrei, W, Schlehofer, B, Scheuchenpflug, T, and Friedenreich, C. (1999) Traditional reviews, meta-analyses and pooled analyses in epidemiology. International Journal of Epidemiology; 28: 1-9.
Cooper, H and Patall, EA (2009) The relative benefits of meta-analysis conducted with individual participant data versus aggregated data. Psychological Methods; 14(2), 165-176.
Jones, AP, Riley, RD, Williamson, PR, and Whitehead, A (2009) Meta-analysis of individual patient data versus aggregate data from longitudinal clinical trials. Clinical Trials; 6: 16-27.
Ragin, C and Taioli, E (2008) Meta-analysis and pooled analysis – Genetic and environmental data. In: Molecular Epidemiology of Chronic Diseases; CP Wild, P Vineis, and S Garte. John Wiley & Sons.
Stewart, LA and Tierney, JF (2002) To IPD or not to IPD? Advantages and disadvantages of systematic reviews using individual patient data. Evaluation & The Health Professions; 25(1): 76-97.
Other related resources
Higgins JPT, Green S (editors). Cochrane Handbook for Systematic Reviews of Interventions. Version 5.1.0 [updated March 2011]. The Cochrane Collaboration, 2011. Available from www.cochrane-handbook.org.
Higgins, JPT, Thompson, SG, Deeks, JJ, and Altman, DG. (2003) Measuring inconsistency in meta-analyses. BMJ; 327(7414): 557-560.
Sterne, JAC, Egger, M, and Moher, D (2011) Chapter 10: Addressing reporting biases. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Stewart, LA, Tierney, JF, and Clarke, M (2011) Chapter 18: Reviews of individual patient data. Cochrane Handbook for Systematic Reviews of Interventions Version 5.1.0 [updated March 2011]. Higgins JPT, Green S (editors). Available from www.cochrane-handbook.org.
Websites
Fixed and random effects: Population Health Methods entry on meta-regression.
Meta-regression may also be used to investigate heterogeneity due to study-level variables. Additional information on this method may be found on the Population Health Methods page on meta-regression.
More information on the PRISMA Statement is available at: http://www.prisma-statement.org/